Background
Previously we explained the use of ID Tokens in applications. Next we will extend the initial SPA and API code sample, to add some essential behaviour related to API authorization and frontend user sessions.
New Features
Our updated SPA and API code sample has the following additional features:
| Feature | Description |
|---|---|
| Claims Based Authorization | The API provides a more complete and future facing claims based authorization solution |
| In Memory Token Storage | The SPA now stores OAuth tokens only in memory, to improve the browser security a little |
| Silent Token Renewal | The SPA now supports silent access token renewal using the SSO Session Cookie |
| Multi Tab Browsing | The token renewal solution enables multi tab browsing without redirecting the user |
| Logout | The SPA implements a basic form of logout, including signing out across multiple browser tabs |
| Developer SSL URLs | Both the SPA and API have been updated to run on a developer PC using real world HTTPS URLs |
Updated Components
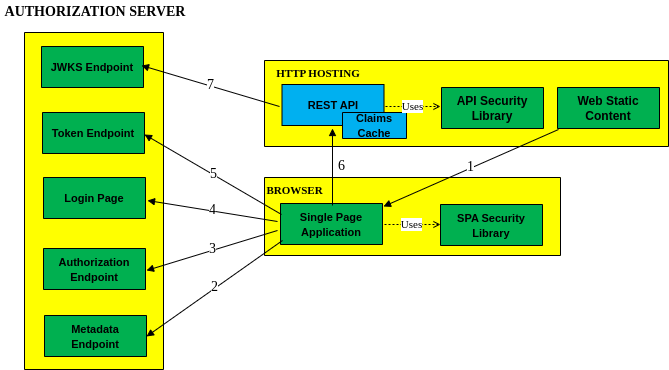
The updated endpoints and components used are shown below, and include a memory cache in the API, use to store values used for authorization:
SPAs in 2021
This sample uses the traditional SPA solution, with OpenID Connect implemented solely in JavaScript. This is no longer recommended, and your production apps should instead use a Back End for Front End approach.
The traditional SPA flow remains useful for representing a pure SPA architecture, and learning about OAuth endpoints and messages. This blog’s Final SPA provides a BFF based solution, but requires a more complex flow.
Code Download
The updated SPA and API code sample can be downloaded from here:
- git clone https://github.com/gary-archer/oauth.websample2
Code Layout
The SPA uses the same components as the initial code sample, with SPA code that runs in the browser and an API back end.
View Updated Configuration
The SPA now uses more complete OAuth settings and SSL based URLs:
{
"app": {
"apiBaseUrl": "https://api.mycompany.com/api"
},
"oauth": {
"provider": "cognito",
"authority": "https://cognito-idp.eu-west-2.amazonaws.com/eu-west-2_CuhLeqiE9",
"clientId": "hje94a2jj3lgkobkh57ikenhh",
"redirectUri": "https://web.mycompany.com/spa",
"postLogoutRedirectUri": "https://web.mycompany.com/spa/loggedout.html",
"scope": "openid profile email https://api.authsamples.com/api/investments",
"customLogoutEndpoint": "https://login.authsamples.com/logout"
}
}The API configuration has been updated in a similar manner:
{
"api": {
"port": 443,
"sslCertificateFileName": "./certs/mycompany.ssl.p12",
"sslCertificatePassword": "Password1",
"trustedOrigins": [
"https://web.mycompany.com"
],
"useProxy": false,
"proxyUrl": "http://127.0.0.1:8888"
},
"oauth": {
"jwksEndpoint": "https://cognito-idp.eu-west-2.amazonaws.com/eu-west-2_CuhLeqiE9/.well-known/jwks.json",
"userInfoEndpoint": "https://login.authsamples.com/oauth2/userInfo",
"issuer": "https://cognito-idp.eu-west-2.amazonaws.com/eu-west-2_CuhLeqiE9",
"audience": "",
"claimsCacheTimeToLiveMinutes": 15
}
}
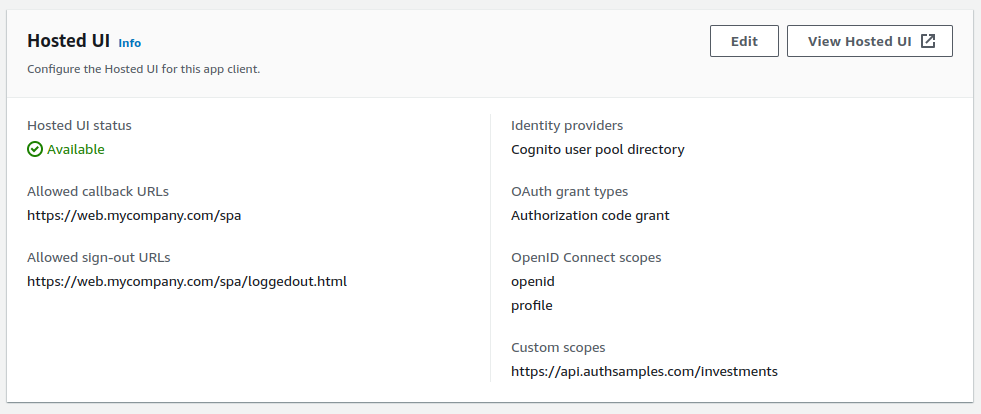
Updated OAuth Client
The SPA now has an updated client registered in the AWS Cognito authorization server, which uses a Custom Scope and a Post Logout Redirect URI:
Build the Code
First run the build script to prepare the SPA and API, which mostly just runs ‘npm install‘ to download dependencies:
- ./build.sh
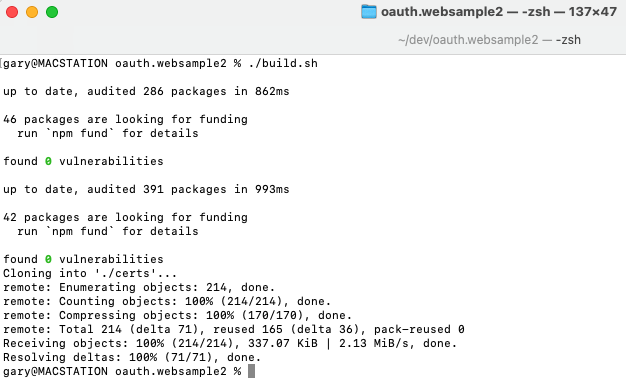
Configure SSL Browser Trust
The build script also downloads OpenSSL generated certificates from a Development Certificates repository to a subdirectory of the API:
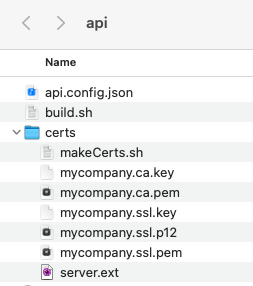
The mycompany.ca.pem file is a root certificate authority that must be added to your system trust store in order for the browser to use SSL without warnings. See the Browser SSL Trust instructions for further information.
Run the SPA and API
Next execute the following script to run SPA and API in separate terminal windows, by running ‘npm start‘:
- ./run.sh
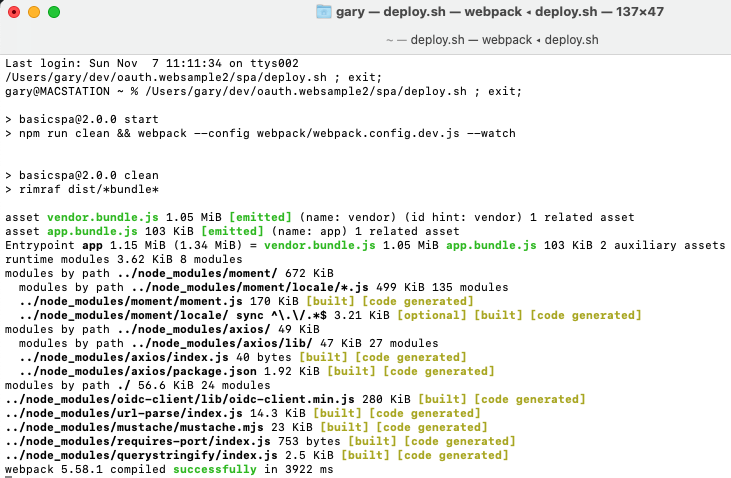
The SPA terminal window builds Javascript bundles:
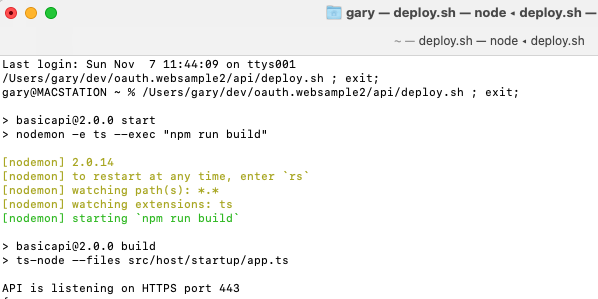
The API terminal window listens for requests from the SPA on port 443:
Test Logins with Multiple User Accounts
The following AWS Cognito test account can continue to be used to sign in to the SPA:
- User = guestuser@mycompany.com
- Password = GuestPassword1
A second test account is also available, with different permissions to the data shown in the SPA:
- User = guestadmin@mycompany.com
- Password = GuestPassword1
The updated SPA then shows different data depending on the user, since the API is now applying claims based authorization.
Updated Access Token
After a login the following access tokens is returned to the SPA. This now contains an investments scope and custom claims for manager_id and role. These values are used by the API for its authorization:
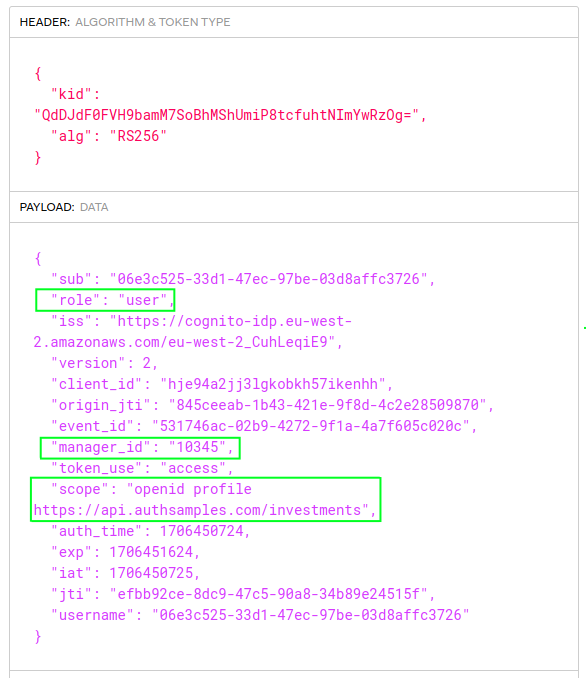
For details on how these scopes and claims are issued from AWS Cognito, see the authorization server setup blog post.
API Claims Based Authorization
The API’s OAuth processing reads the token claims and also looks up extra values needed to implement its authorization. Further details on design choices are provided in the API Authorization Design blog post.

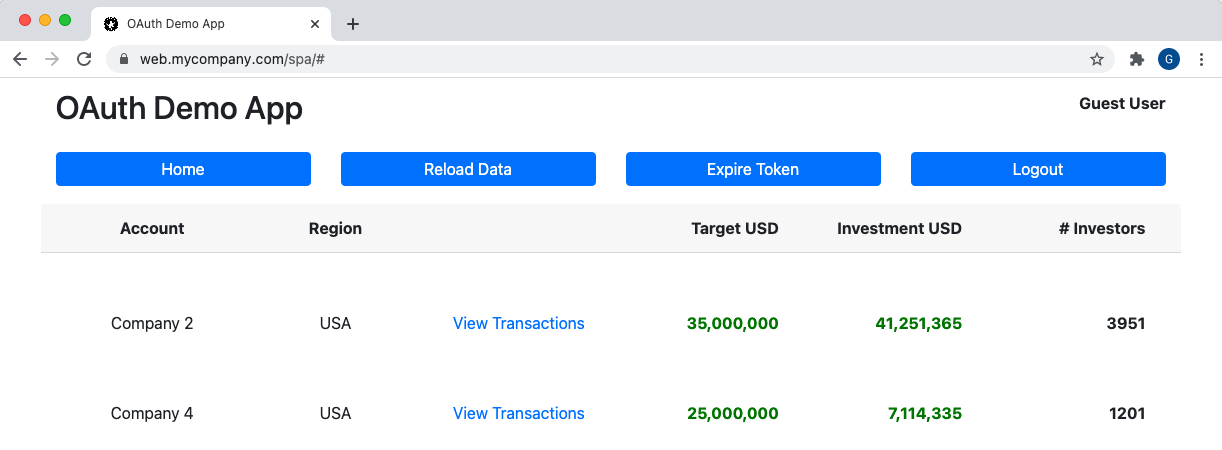
The API serves hard coded JSON data, representing multiple regions:
[
{
"id": 1,
"name": "Company 1",
"region": "Europe",
"targetUsd": 20000000,
"investmentUsd": 13801299,
"noInvestors": 2310
},
{
"id": 2,
"name": "Company 2",
"region": "USA",
"targetUsd": 35000000,
"investmentUsd": 41251365,
"noInvestors": 3951
}
]Each user has access to data from an array of regions, and the default guest user only has access to the US region, so cannot see items 1 and 3 above. Therefore these items are filtered out of the company list:
In the transactions view, if the user tries to access company 3 by editing the browser URL, the API denies access and returns a 404 response with a company_not_found error code.
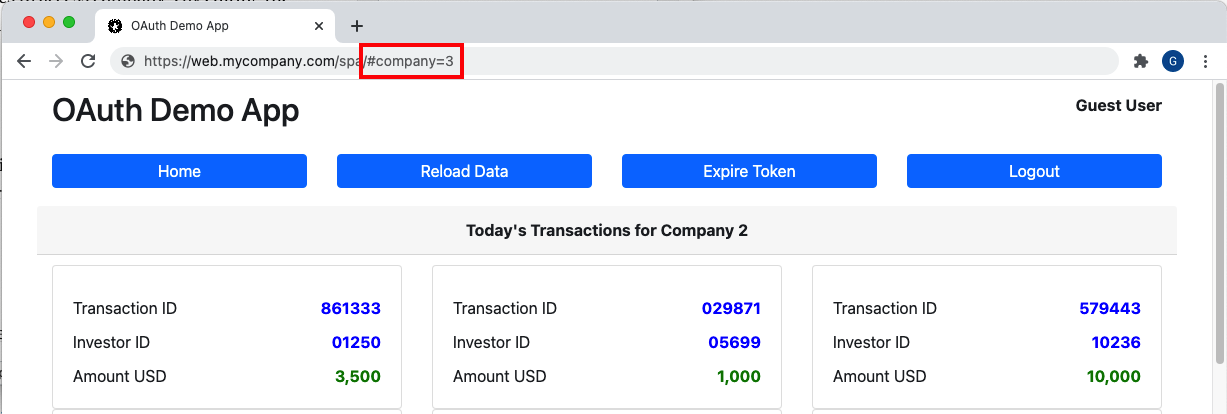
The SPA handles this ‘not found for user‘ API error code specially and redirects to the home page, so that we avoid presenting an error display to the end user.
SPA Downloads User Info
As for the first code example, the SPA continues to get name details for display from the OAuth user info endpoint. Note that AWS Cognito does not allow the user info payload to be customized:
{
"sub": "06e3c525-33d1-47ec-97be-03d8affc3726",
"custom:manager_id": "10345",
"email_verified": "true",
"given_name": "Guest",
"family_name": "User",
"custom:role": "user",
"email": "guestuser@mycompany.com",
"username": "06e3c525-33d1-47ec-97be-03d8affc3726"
}The SPA also calls a user info endpoint in its own API, to get secondary user attributes, which are not stored in the identity data:
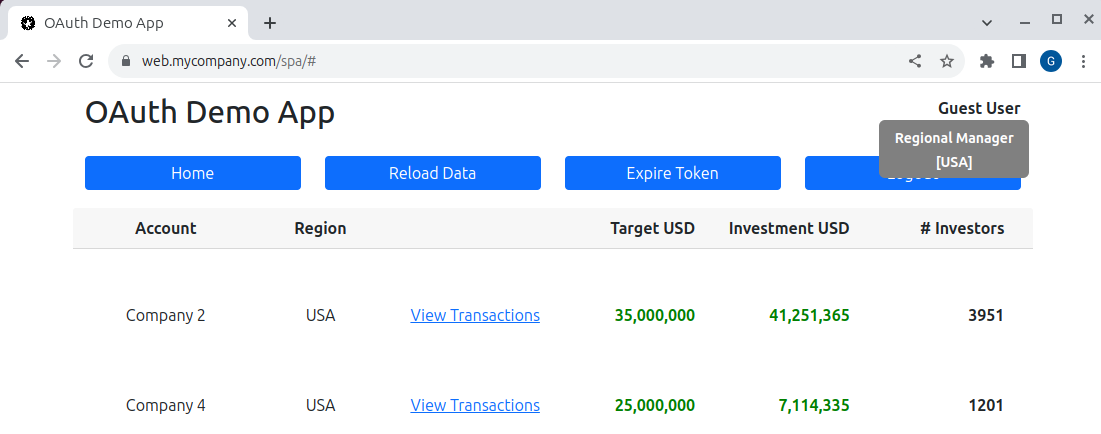
{
"title":"Regional Manager",
"regions":["USA"]
}The secondary user data is then rendered in a basic tooltip:
Triggering Token Renewal
The SPA now refreshes in-memory access tokens silently when they expire. This can be simulated by clicking Expire Token then Reload Data:
Since tokens are stored in memory, the same renewal occurs if the browser page is refreshed or the user performs multi tab browsing:
The following actions should then take place:
- The SPA receives a 401 response from the API
- A silent iframe token renewal redirect is triggered, using the SSO cookie
- A new access token is received without impacting the user
- The API call is retried with the new token, which then succeeds
Token Renewal
The updated code sample implements the traditional SPA token renewal flow, where the SPA attempts to get a new access token by sending the SSO cookie with the ‘prompt=none‘ query parameter:
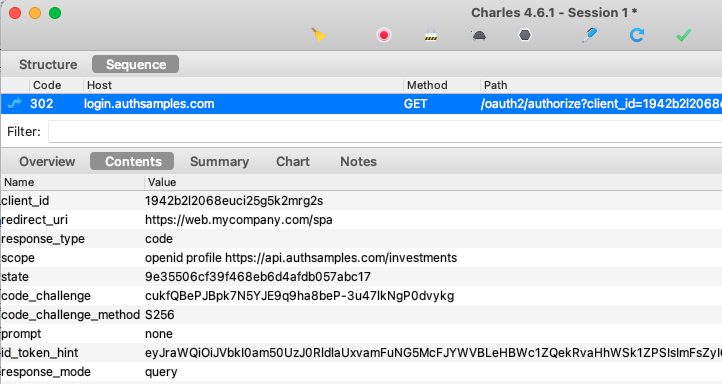
Yet AWS Cognito is not compliant with the iframe renewal flow, so when it is configured as the authorization server, the SPA falls back to using a refresh token to renew access tokens:
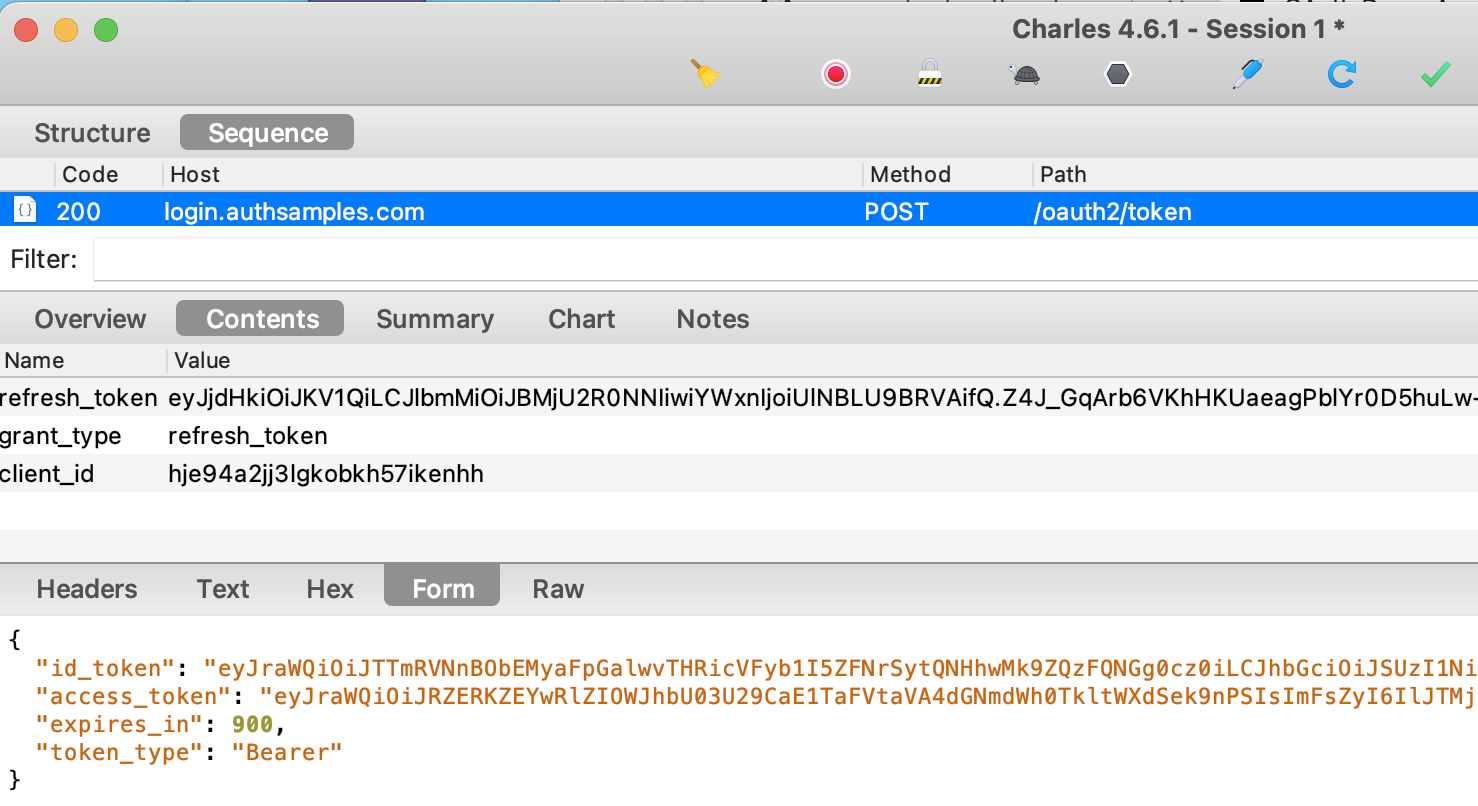
Despite code being written correctly, these renewal flows are unsatisfactory from a security and reliability viewpoint. For further details on issues, see the IFrame Access Token Renewal post.
Logout
We have also implemented our Logout Behaviour, and after logout we return to a Post Logout Landing Page:

A boolean flag is also stored in session storage after logout. Other tabs use the browser’s storage events to listen for this value being set, then remove tokens from memory and move to the logged out page:
Where Are We?
We have added missing features to our code sample, to improve SPA session management and to enable the API to authorize requests correctly. There are some open issues, and these will be resolved later, in the Final SPA.
Next Steps
- We will look at Coding Key Points for the updated SPA
- For a list of all blog posts see the Index Page